This article was previously published on LinkedIn
There’s not really such as thing as “advanced TDD”, other than practising TDD more diligently, writes Esko Luontola.
I experienced this directly when working on my hobby project this month. I’m trying to code the rules to a boardgame that is regarded as pretty simple by the boardgaming community (it has a complexity score of 2.69 over 5 on Boardgamegeek). It is however orders of magnitude more complicated to code than, say, Force 4 or Chess.
One rule of this game that it took me a long time to get right is the one around retreats. It goes like this: when one of my units attacks another unit, I roll a number of special dice, whose sides depict various symbols. Some symbols, when they turn face up, inflict damage on the opponent’s unit. The “flag” symbol is special: it means that the unit is expected to retreat some hexes (1, 2, 3 or 4 hexes, depending on the defending unit’s speed). There are a number of complications:
- If more than one flag is rolled, the number of hexes that the unit must retreat is multiplied by the number of flags
- If the defending unit’s retreat path is blocked, it receives one point of damage for every retret hex not taken
- If the defending unit has “support”, meaning it is adjacent to at least two friendly units, the defending player may decide to ignore one flag result
- If ignoring one flag would result in the defending unit taking damage, then it is not allowed to ignore the flag; that is, the defending player must always play so to minimize damage to the defending unit.
The above rules apply in the middle of the close combat procedure, which in turn has other complications, such as that if the defending unit does not die and does not retreat, it is entitled to battle back, and other things.
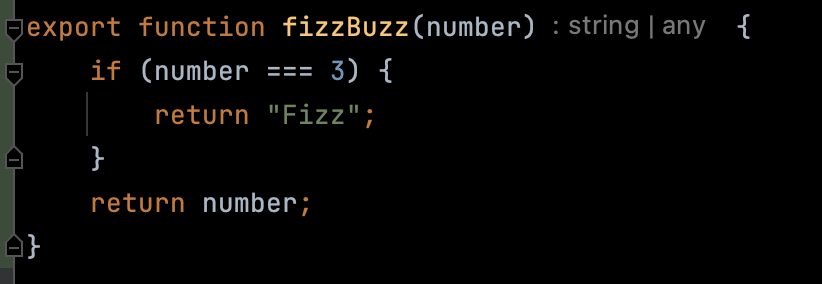
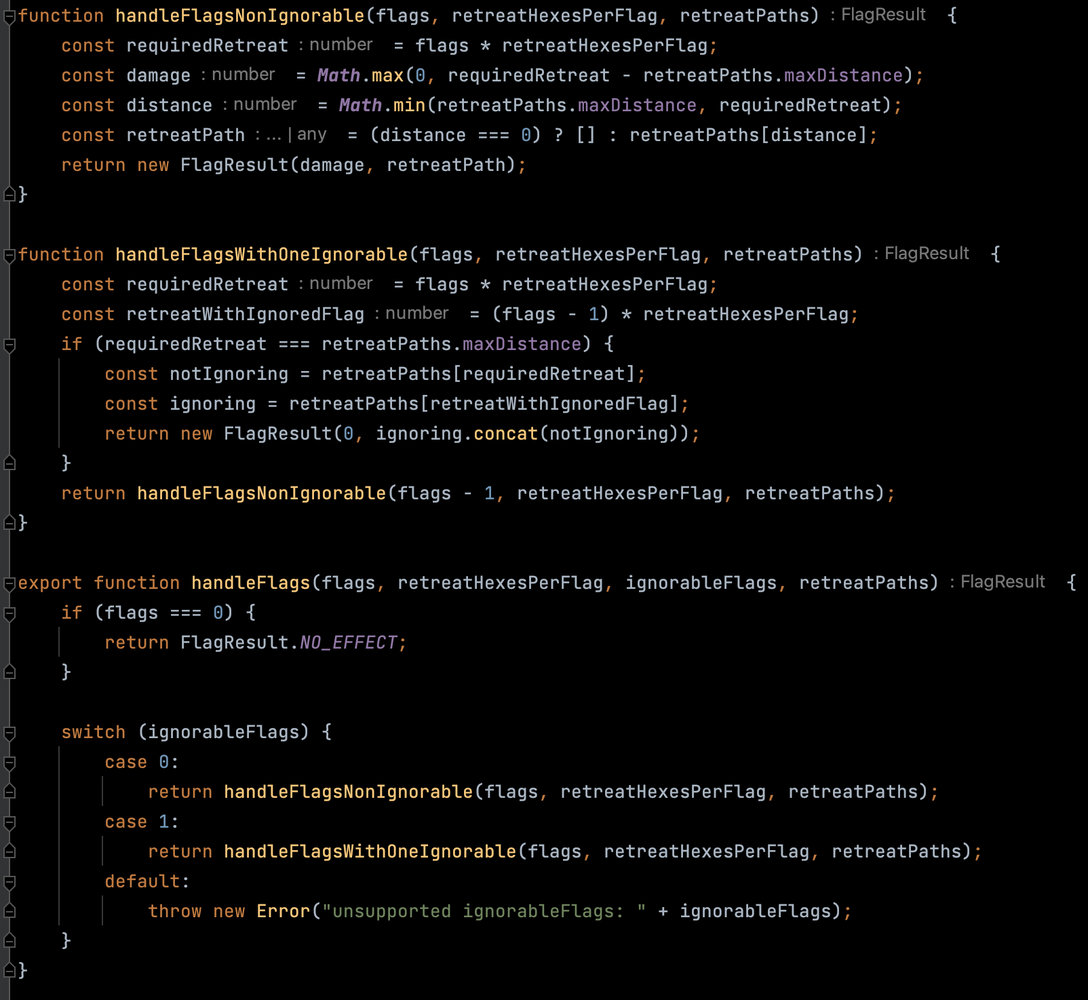
My first idea was to single out the retreat logic in a pure function; pure in the sense that this function should not move units around on the board, take decisions, or apply damage. I wanted to focus on inputs (the dice results, the situation on the board) and the outputs: how much damage the defending unit should take, and what are the move options that the defending player must choose from. Instead of coding a function that acted on the model, I wanted a function that returned a data structure that represents the actions to be taken. I think I learned this trick from a blog by Jessica Kerr that I now am no longer able to find, where she called it the “super simple approach”, or something like this.
I then proceeded to implement this, writing tests first. It did not go well! This is my git log:
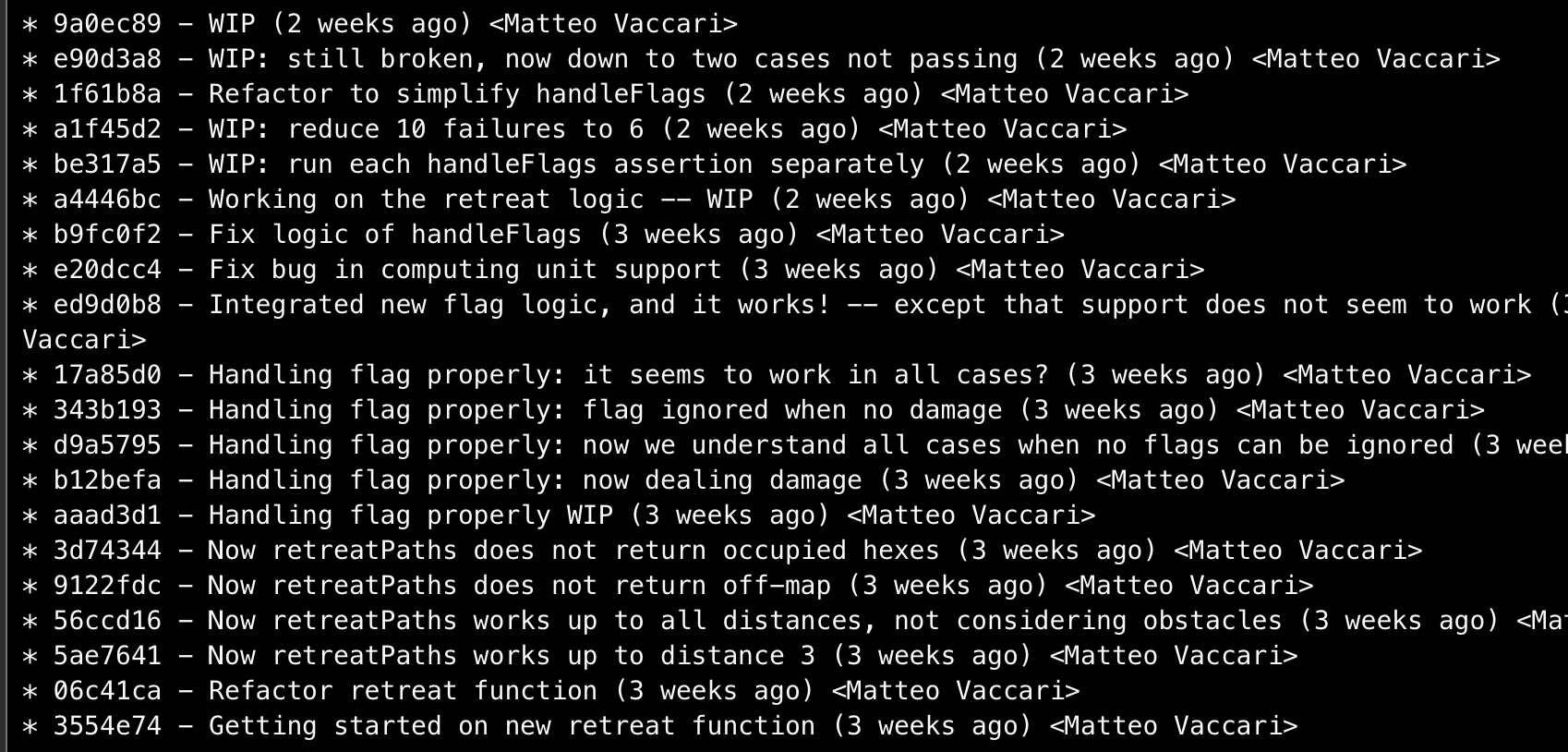
The code I had at 9a0ec89 looked like this: horribly complicated, and not working correctly. There are also signs of debugging via console logs, another indication that my effort was failing.
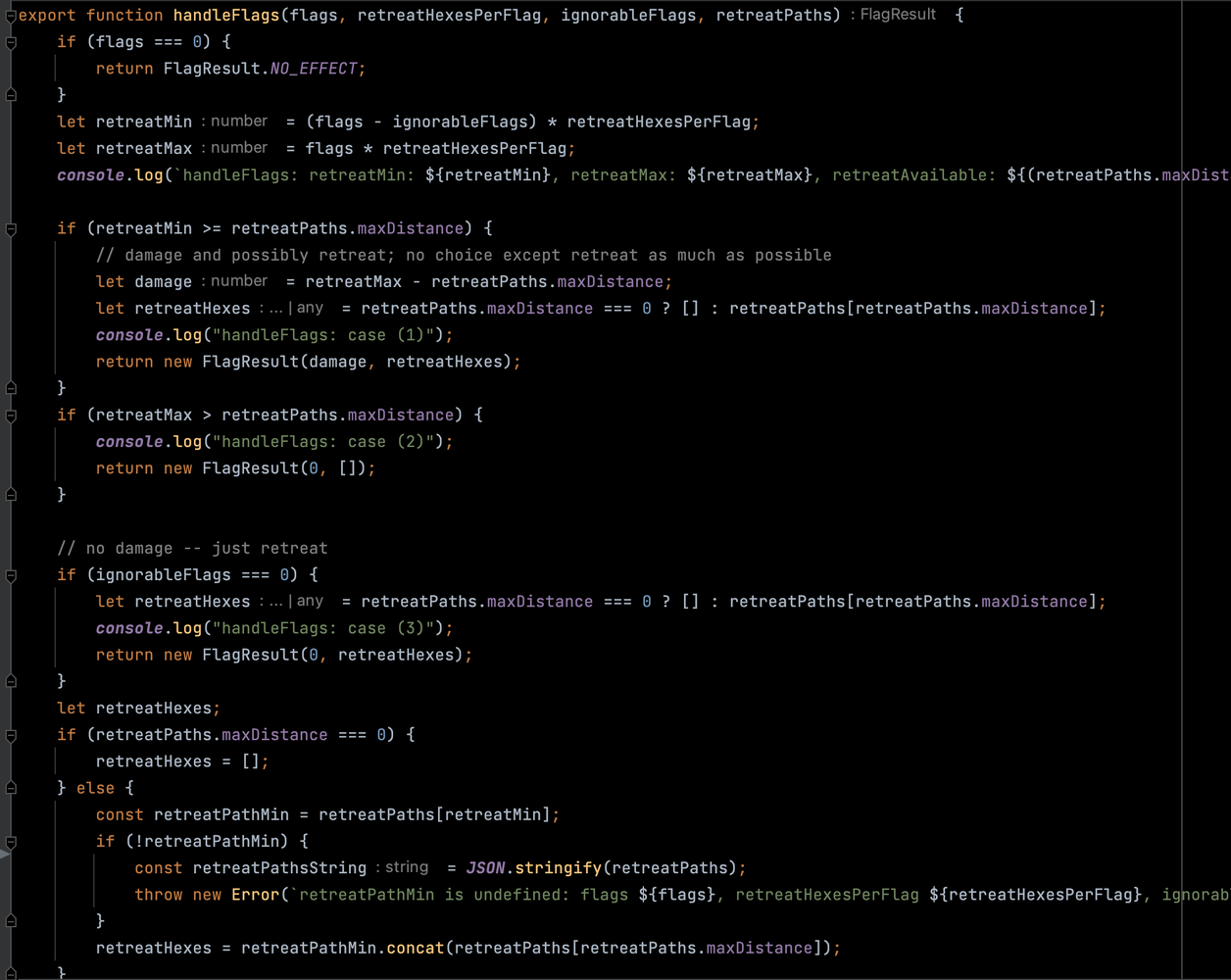
What went wrong? I took large steps. I tried to guess the correct algorithm too early. I forced myself to continue even though I was tired. Then I did the right thing: throw away the code and start from scratch!
This time I decided to try and follow TDD more carefully. Small steps and fake it. “Fake it” means that when I write a new failing test, I make it pass by returning the exact value that the test expects. It may look like cheating and wasting time; in fact, when we teach TDD we often hear complaints from learners about fake it. They tell us “this is silly; surely we don’t do this in real work”. Sometimes I hear this so much that I start to believe it; yet this programming episode reminded me that it’s when the going gets tough that you really need to shift to a low gear, go slowly, apply the TDD process as well as you can, and take really small steps. My git log after this has a different tone:
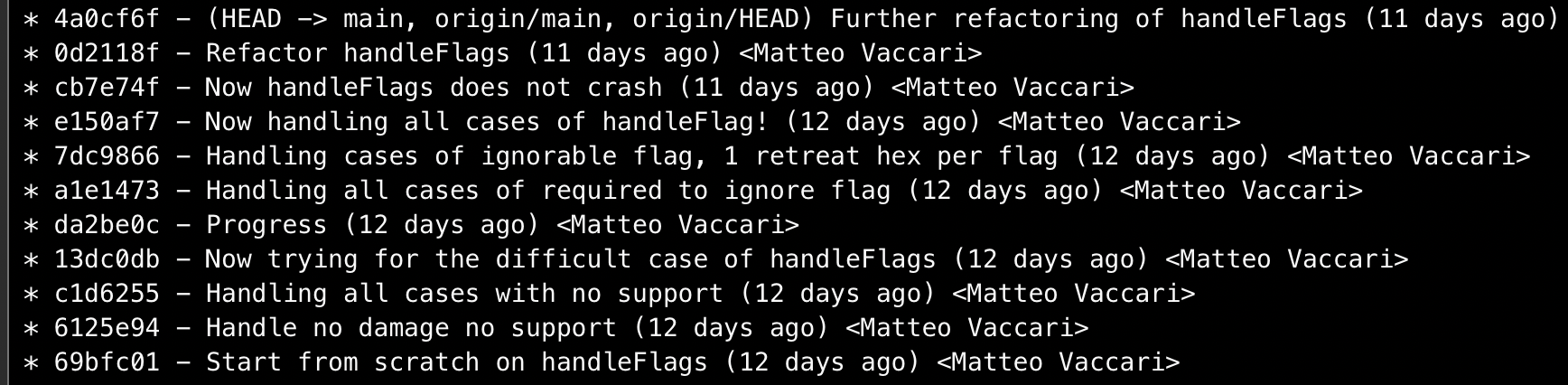
and the code today looks quite different:
Thanks to 👨💻 Esko Luontola, J. B. Rainsberger, GeePaw Hill, Jessica Kerr for learnings and inspiration. And of course Kent Beck!